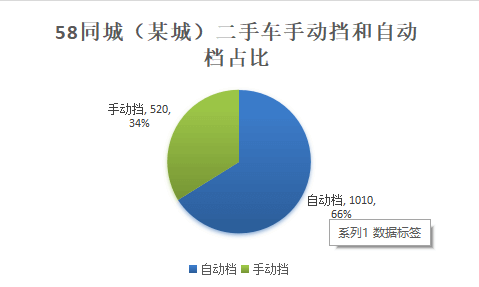
使用 Python 写了个爬虫以爬取58同城某个城市的二手车数据,总共爬取了 1530 条数据。通过数据可以得出一些结论,比如66%的车都是自动档,只有34%的车是手动挡,而这些车首次挂牌时间按数量排序主要集中在2012年、2011年、2010年这三个时间,
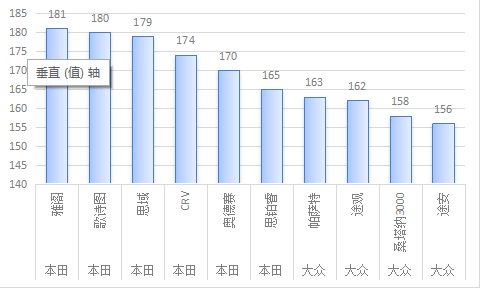
按照购买车型的数量排序前10名来看,本田的雅阁系列最受欢,还可以看出来购买最多的品牌是本田,其次是大众。
购买汽车的油箱容量大多数都是 2L ,其次是 2.4L 和 1.6L 汽油容量的汽车,这说明中国人的中庸之道运用的非常到位。
附上爬虫源码,先自我评价一番,代码写得不好看,还是需要多多练习,学习别人的写法。Excel 也需要多练练了,数据分析部分太粗糙。
未完待续,爬取58同城二手车数据目的是为了学习数据分析,待我学成归来展现更加精致的分析结果。
# -*- conding: utf-8 -*-
import time
import requests, lxml
from bs4 import BeautifulSoup
from openpyxl import Workbook
def get_page(url):
global page
headers = {
'Accept':'*/*',
'Accept-Encoding':'gzip, deflate',
'Cache-Control':'no-cache',
'Connection':'keep-alive',
'Host':'cdata.58.com',
'Referer':'http://xxxx.58.com/',
'Accept':"text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8",
'User-Agent': 'User-Agent:Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'
}
re = requests.get(url, timeout=6)
page = BeautifulSoup(re.text,'lxml')
return page
def get_car_info(page):
for car_info in page.find_all('li',{'class':'clearfix car_list_less ac_item'}):
for car_name in car_info.find_all('h1',{'class':'info_tit'}):
car_name = car_name.get_text(strip=True)
for car_info_param in car_info.find_all('div',{'class':'info_param'}):
car_info_param = car_info_param.get_text('|',strip=True)
car_info_param_list = car_info_param.split("|")
car_year = car_info_param_list[0]
car_distance = car_info_param_list[1]
car_volume = car_info_param_list[2]
car_model = car_info_param_list[3]
for car_price in car_info.find_all('div',{'class':'col col3'}):
car_price = car_price.get_text(strip=True)
ws.append((car_name,car_year,car_distance,car_volume,car_model,car_price))
def main():
global ws
wb = Workbook()
ws = wb.active
url = 'http://xxxx.58.com/ershouche/'
num = 0
while True:
num += 1
try:
page = get_page(url)
get_car_info(page)
url = 'http://bygl.58.com' + page.find('a',{'class':'next'}).attrs['href']
time.sleep(3)
except IndexError as e:
input('error:',e)
break
except Timeout as e:
print('error',e)
else:
print('download',num)
finally:
wb.save('car_info.xlsx')
if __name__ == '__main__':
main()
发表回复