上一篇文章爬取了58同城网的二手车数据,但是只用Excel进行了简单的分析,现在开始使用Python的第三方科学计算库Pandas、Numpy来分析一下数据,并绘出图标进行展示,先看一看之前爬虫保存的数据成果:
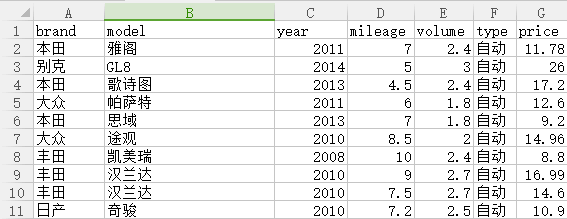
- brand:品牌
- model:型号
- year:首次上牌时间
- mileage:里程数,单位为万公里
- volume:油箱容量
- type:自动挡还是手动挡
- price:价格,单位为万。
数据结构大体如此,现在开始用Python分析它,首先电脑需要安装有Pandas、Numpy,如果使用Pandas打开表格文件(.xlsx),还需要安装一个 xlrd,绘画图表需要 matplotlib 库。如果现在还没有安装,使用 pip 安装它们也非常简单。
pip install pandas numpy xlrd matplotlib现在就可以导入模块,读取我们的58同城二手车的表格数据 cars_info.xlsx,由于我们的表格中含有中文,所以开始应该先声明编码。
# -*- conding: utf-8 -*-
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import xlrd
from pandas import DataFrame,Series
cars_info = pd.read_excel('car_info.xlsx')OK,已经成功读取了我们的数据,就像之前用Excel分析的那样,我们先来统计一下自动档和手动挡各有多少。
type_rank = cars_info['type'].value_counts()
>>> type_rank
自动 1063
手动 533
Name: type, dtype: int64便捷快速的计算出了两个档型各有多少个,接着使用 matplotlib 把数据绘画成图表。
plt.show(type_rank.plot.pie(labels=['Automatic','Manual'],autopct='%0.2f%%',shadow=True))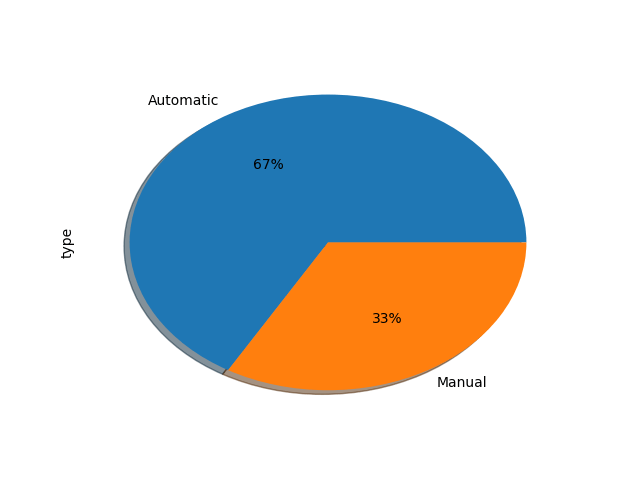
plt.show()方法可以直接显示图片type_rank.plot.pie(),pandas对象有个plot方法可以绘图,pie可以绘画饼状图- labels=[‘Automatic’,’Manual’],标签名称,默认原本应该是显示自动、手动,但是其本身对中文支持并不良好,可以通过一定的方法实现中文支持,但是在这里直接改成英文更加简单一些。解决中文支持问题也是必要的,也可以查看我原先的博文解决这个问题:matplotlib解决中文支持。
- autopct=’%0.2f%%’,饼状图内的文本格式,
%0.2f%%意味着浮点数保留两位小数,并且格式化为百分号的形式。第一个零表示不控制总长度(无论整个数字有多长),第二个 2f 表示小数点后保留两位,后面的一个百分号表示格式化为百分比。 - shadow=True,饼状图的阴影显示,只影响图表外观。
暂时拉回数据分析话题本身,实际上自动挡车比手动挡车数量多那么多,这是让我有些意外的,那么自动挡的车和手动挡的车的数量随时间变化时什么关系呢?继续分析自动挡和手动挡车随着时间的变化,这里就用到了groupby()方法来分组:
cars_info.groupby(['year','type']).size().unstack().plot(kind='bar')size()方法用于计算组(groupby)的数量,在这里正好用到了统计数量方面,unstack() 解开了多层索引,把 type 从索引转移到列上。kind 参数用于指定图表的类型,而 plot 默认生成是曲线图,可以通过设定 kind 参数生成其他的图形,可选的值为:line, bar, barh, kde, density, scatter。接着看看我们生成的结果:
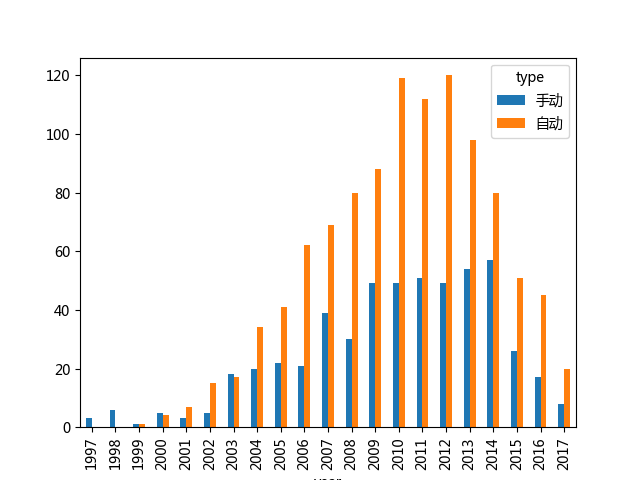
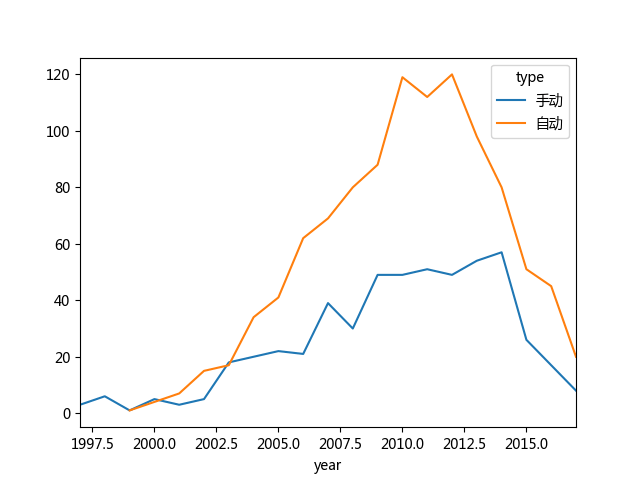
图表显示的结果一目了然,从2000年开始自动挡车的数量就开始增加,和手动挡差距越来越大直到2012年不断减少和手动挡车数量比。从图中可以看到这些含义,抛开图表我们也需要想一想,我们的数据本身是否存在什么问题。第一,我们的数据源是从网上获取的,抛开数据本身的真实性不谈(真实性影响因素很多),单单是车主在互联网上卖二手车这一点,是否会存在一种反向选择的倾向呢?我是说,喜欢用互联网的人更倾向于在互联网上卖二手车,那么喜欢互联网的人是否更倾向于购买自动挡车呢?
好了~继续回到 Pandas 时间~到了这里,我们还想比较一下相关性,和价格相关的因素有哪些呢?或者说和价格相关因素哪个相关性更强呢?DataFrame 对象有个 corr() 方法可以用来计算相关性,来画个图看看~
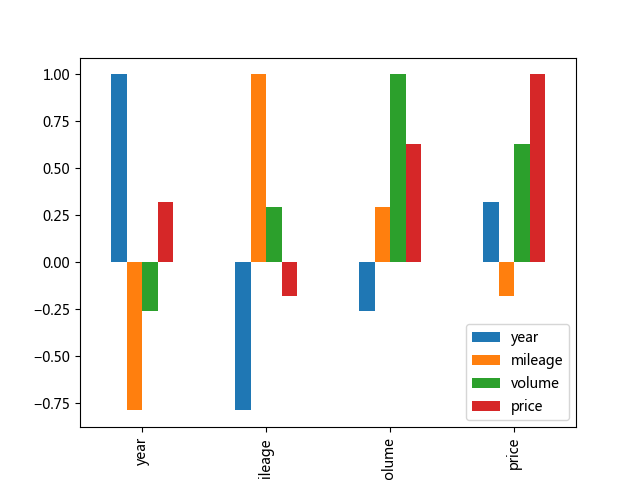
咳咳~准确的说,里面有一些重复部分,你会发现第一个、第三个分别是第二个、四四个的对称版,并且有些信息是不必要的,比如时间 year 当然和时间本身具有完全的相关性,所以值为 1。除了这些槽点,我们会发现油箱容量和二手车价格相关性达到了 0.6,具有很强的相关性,而里程数和价格也具有相关性却不明显,难道不是车开的越多折旧越多吗?这可能是禀赋效应在作怪~然后就是首次上牌日期和价格的相关性,首次上牌日期越晚,那么车就越新,然后价格就越贵,这个没毛病。
上列的相关性是所有车型一起统计的,一些方面太不严谨了,这里选择数据最多的车型为雅阁,再次分析一下相关性:
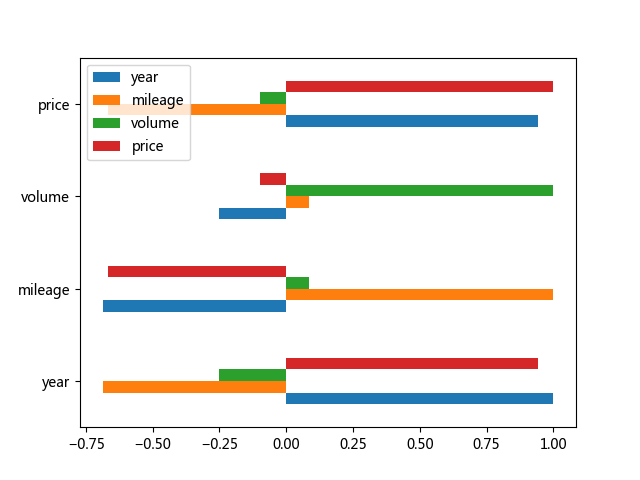
这次的相关性数据就没啥说的了~全部符合常识,最后再看一看售卖的二手车最多的品牌和型号是什么?
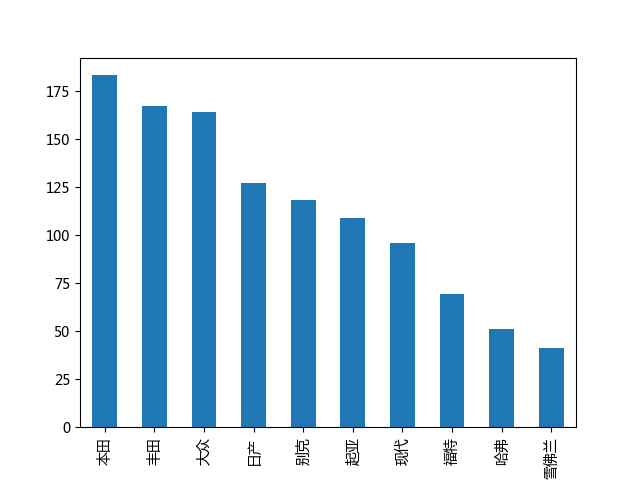
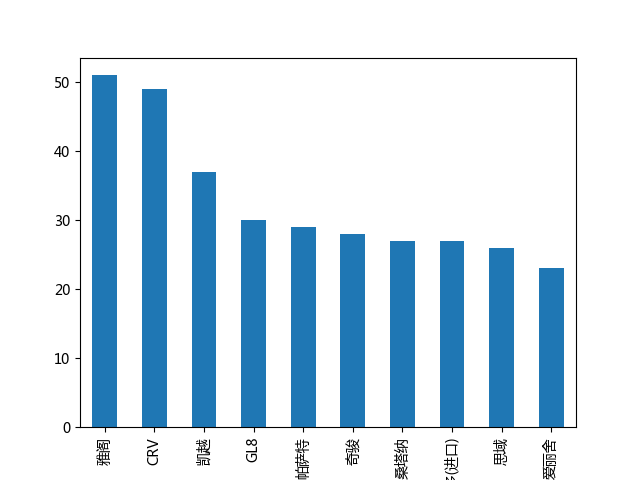
完~~~
发表回复