从学习Python的第八天就想要写个简单爬虫,当天就实现了功能,不过遇到了点问题,之后两天也都一一解决了。初学编程语言时写个小作品是令人兴奋的,这对学习过程来说是个很大的激励,所以我向来遵循Learning-by-doing。Learning-by-doing这容易联想到古典经济学的一个名词,被国人简单粗暴的翻译为“干中学”,意为在实践中学习。
2017.10.18:更新
无意中想到这个在初学 Python 时写的小玩具,代码很乱并且复用性很差,所以想到把这个小玩具重写一遍,虽然意义不大,写代码本身的乐趣已经远远超过代码能做的事情。把整个下载文件的爬虫分割成了几个部分:
def MKdir(dirname):
if not os.path.isdir(dirname):
os.mkdir(dirname)
return os.path.abspath(dirname)创建了 MKdir() 函数来创建一个文件夹, os.path.isdir() 方法可以检测文件夹是否存在,如果存在则返回 True ,反之则返回 False 。MKdir() 函数可以检测文件夹是否存在,如果不存在则新建一个,然后返回文件夹路径。
def Get_res(url):
headers = {
'Referer':'http://jandan.net/ooxx',
'User-Agent': 'User-Agent:Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'
}
try:
Re = requests.get(url,headers=headers,timeout=6)
except Timeout as e:
print('请求超时:',e)
except ConnectionError as e:
print('请检查网络连接:',e)
except HTTPError as e:
print('网页错误:',e)
return Re返回一个 requests 的实例 Re,由于错误处理的部分还是比较长的,所以拆成了一个函数~
def Download_Img(url,name):
if os.path.exists(name):
exist_name = os.path.split(name)[1]
print('{0}文件已经存在!'.format(exist_name))
res = Get_res(url)
with open(name,'wb') as f:
for chunk in res.iter_content(100000):
f.write(chunk)下载图片的函数,检测文件是否存在,如果不存在使用 open() 以二进制写入方式打开一个文件,使用 res.iter_content(100000) 迭代器每次返回写入 100000 字节的内容写入文件。 在这里有些人大概会有疑问,为什么要使用 res.iter_content() 迭代器,而不是使用 res.content() 一次性下载写入内容,这是为了避免下载大文件时占用掉所有内存,所以每次迭代的写入 10万 字节是一个好主意。
def Get_img_list(url):
Re = Get_res(url)
page = BeautifulSoup(Re.text,"lxml")
img_url_list = [ ]
for i in page.ol.find_all('img'):
img_url_list.append(i.attrs['src'])
return img_url_list这是作为爬虫本身的核心代码,通过分析网页源码可以发现,煎蛋网爬虫的代码都在 ol 标签块下,使用 BeautifulSoup 获取 ol 标签中所有带有 img 标签的链接,并且加入到 img_url_list 列表中。
def new_url(url):
Re = Get_res(url)
page = BeautifulSoup(Re.text,"lxml")
new_url = page.find("a",{"class":"previous-comment-page"}).attrs['href']
return 'http:'+new_url在查看煎蛋网的页面源码时可以发现,上一页按钮的链接都含有一个属性 {“class”:”previous-comment-page”} ,那就好办了,连正则表达式都不需要了,直接用美味的汤(BeautifulSoup)就直接扣出来了。由于网站引用的图片是新浪图片,并且以相对链接形式 “//” 开头,而不是 ‘http://’ ,所以 http 这部分就需要自己合成了。
在分割图片链接的文件名时,原本是使用的正则表达式,后来灵感一闪,想到了 os.path.split() 模块不就是干分割文件名的嘛,其本身就只是操作 str 数据类型的文本,所以尝试了一下果然可以。
os.path.split('https://yearliny.com/favicon.ico')在IDLE下运行,可以正常返回一个包含两个数据的元组,完美分割为:
("https://yearliny.com/","favicon.ico")最后附上完整源码:
# -*- coding: utf-8 -*-
import os
import lxml
import requests
from bs4 import BeautifulSoup
# check dir exist,if don't creat a new
def MKdir(dirname):
if not os.path.isdir(dirname):
os.mkdir(dirname)
return os.path.abspath(dirname)
def Get_res(url):
headers = {
'Referer':'http://jandan.net/ooxx',
'User-Agent': 'User-Agent:Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'
}
try:
Re = requests.get(url,headers=headers,timeout=6)
except Timeout as e:
print('请求超时:',e)
except ConnectionError as e:
print('请检查网络连接',e)
except HTTPError as e:
print('网页错误:',e)
return Re
# Download_Img(url,name),download a file,name contain path
def Download_Img(url,name):
if os.path.exists(name):
exist_name = os.path.split(name)[1]
print('{0}文件已经存在!'.format(exist_name))
res = Get_res(url)
with open(name,'wb') as f:
for chunk in res.iter_content(100000):
f.write(chunk)
# return a list of image
def Get_img_list(url):
Re = Get_res(url)
page = BeautifulSoup(Re.text,"lxml")
img_url_list = [ ]
for i in page.ol.find_all('img'):
img_url_list.append(i.attrs['src'])
return img_url_list
def new_url(url):
Re = Get_res(url)
page = BeautifulSoup(Re.text,"lxml")
new_url = page.find("a",{"class":"previous-comment-page"}).attrs['href']
return 'http:'+new_url
def main():
page_num = int(input("How many pages you want to download?(About 8 images per page):"))
page_url = "http://jiandan.net/ooxx"
img_num = 0
path = MKdir('jiandan')
for n in range(page_num):
img_list = Get_img_list(page_url)
for i in img_list:
img_num += 1
img_url = 'http:' + i
img_name = os.path.split(img_url)[1]
img_path = os.path.join(path,img_name)
Download_Img(img_url,img_path)
print('{0} Downloading >> {1}'.format(img_num,img_name))
page_url = new_url(page_url)
print('Thanks you!All done!You have downloaded %d images.' % img_num)
if __name__ == '__main__':
main()
这是一个非常简单的爬虫,在此发表一来作为学习记录,二来可以给和我一样的初学者提供一些参考。写爬虫的过程中,遇到的第一个问题就是爬6页就会被403禁止了。当我写好爬虫运行,一张张图片稳妥的下载到了硬盘中,于是准备泡一杯茶优雅的看着爬虫输出一条条胜利的消息,结果回来后看到了爆出的红字错误。 于是就想到了模拟UA,在了解这方面的使用方法时知道了Requests这个模块,于是就好好的了解了一下requests模块,看了官方文档后果然入其所说的那般简单优雅,API的易用性胜于urllib,修改headers只需要一行:
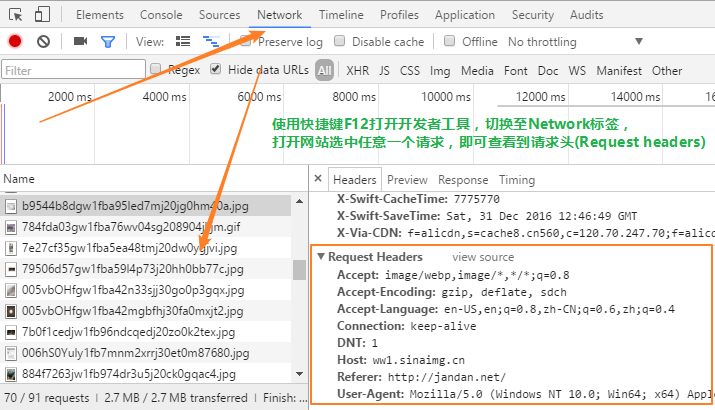
requests.get(url,headers = {'User-Agent': 'User-Agent:Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'})不知道煎蛋网检测机器人是根据什么特征判断的,所以把本机浏览器的headers全部修改成自己浏览器的header,查看本机headers就需要用到chrome的开发者工具(chrome-devtools):F12打开开发者工具并切换到Network标签,访问任意网站,查看任意一个GET请求,就能够知道自己浏览器的headers了。
最后附上源码。(注:需要安装所需模块,否则无法正常运行,模块安装不成功看这里)
pip install BeautifulSoup4 requests lxmlfrom bs4 import BeautifulSoup
from urllib.request import urlretrieve
import requests
import lxml
import re
page_num = int(input("How many pages you want to download?(1~99):"))
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, sdch',
'Accept-Language':'en-US,en;q=0.8,zh-CN;q=0.6,zh;q=0.4',
'Connection': 'keep-alive',
'Referer':'http://jandan.net/ooxx',
'User-Agent': 'User-Agent:Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36',
'Accept-Charset': 'ISO-8859-1,utf-8;q=0.7,*;q=0.3'
}
page = BeautifulSoup(requests.get("http://jiandan.net/ooxx",headers = headers).text,"lxml")
img_num = 0
def get_img():
global img_num
for i in page.findAll("a",{"class":"view_img_link"}):
img_url = ("http:"+i.attrs['href'])
img_name = re.search(r"\w*.(jpg|gif|png)",img_url).group(0)
urlretrieve(img_url,img_name)
img_num += 1
print("Downloading..."+ img_name)
def new_url():
new_url = BeautifulSoup(requests.get(page.find("a",{"class":"previous-comment-page"}).attrs['href'],headers = headers).text,"lxml")
return new_url
for n in range(page_num):
get_img()
page = new_url()
print('Thanks you!All done!You have downloaded %d images.' % img_num)
发表回复